Prisma Migrate 怎么用?——复盘总结
什么是 ORM
ORM(Object-relational mapping),中文翻译为对象关系映射,是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。 简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。[1]
Prisma Migrate 的用作是什么
如 ORM 定义的一样,ORM 框架一般提供一种操作对象就可以操作数据库的能力,更方便我们在当前所处的编程语言当中完成对数据的操作。Prisma 就是一款常用的 JS/TS ORM 框架。
Prisma 当中定义结构的方法就是 schema.prisma 文件,这个文件描述了数据库的结构在 JavaScript 中是如何定义的,通过操作这些对象的方式就可以操作数据库了。
理想的情况是我们开发的时候只操心这个 schema.prisma 文件就可以了。
假如我们的项目和数据库中有一个 User 结构:
/// schema.prisma
model user {
id Int @id @default(autoincrement())
name String?
password String? @db.VarChar(64)
}那么如果你想给这个结构中加一个 用户创建时间 的字段的时候,应该如何操作呢?
按照我们理想情况,我们只需要操作这个 schema.prisma 文件就可以对数据库进行变更。
Prisma Migrate 就可以帮我们完成这次变更,不仅如此 Prisma Migrate 还可以帮我们管理好每一次变更。
初始化项目
在完整的 Prisma 项目的流程中,我们应该从初始化开始使用 Prisma Migrate
prisma migrate dev --name init这个操作会将 prisma 结构同步到数据库当中,并创建一个 migrations 记录:
migrations/
└─ 20241122022542_init/
└─ migration.sql默认的 migrations 记录都是以时间开头 + 下划线 + 名称。
migration.sql 内容将会是修改数据库使用的 SQL:
-- CreateTable
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255),
password VARCHAR(64)
);继续修改数据库
现在我们在之前的结构中加入 用户创建时间 这个字段
/// schema.prisma
model user {
id Int @id @default(autoincrement())
name String?
password String? @db.VarChar(64)
+ createdAt DateTime @default(now()) @map("created_at")
}如要更改的时候继续使用 prisma migrate dev 命令
prisma migrate dev --name added_user_createat这时候我们创建了第二个迁移,同时数据库结构也与 prisma 结构同步
migrations/
└─ 20241122024309_added_user_createat/
└─ migration.sql
└─ 20241122022542_init/
└─ migration.sqlmigration.sql 内容还是修改数据库使用的 SQL:
-- AlterTable
ALTER TABLE user ADD COLUMN created_at DATETIME DEFAULT CURRENT_TIMESTAMP;现在,你已经有了项目完整的迁移记录,你可以将这些记录文件加入到 Git 当中进行保存,并将其部署到测试环境和生产环境。
部署到测试环境和生产环境
直接同步
将 Prisma 结构和数据库结构同步有两种最简单的办法
prisma db push

prisma db pull
如果需要强行覆盖本地 Prisma 结构可以使用 prisma db pull --force
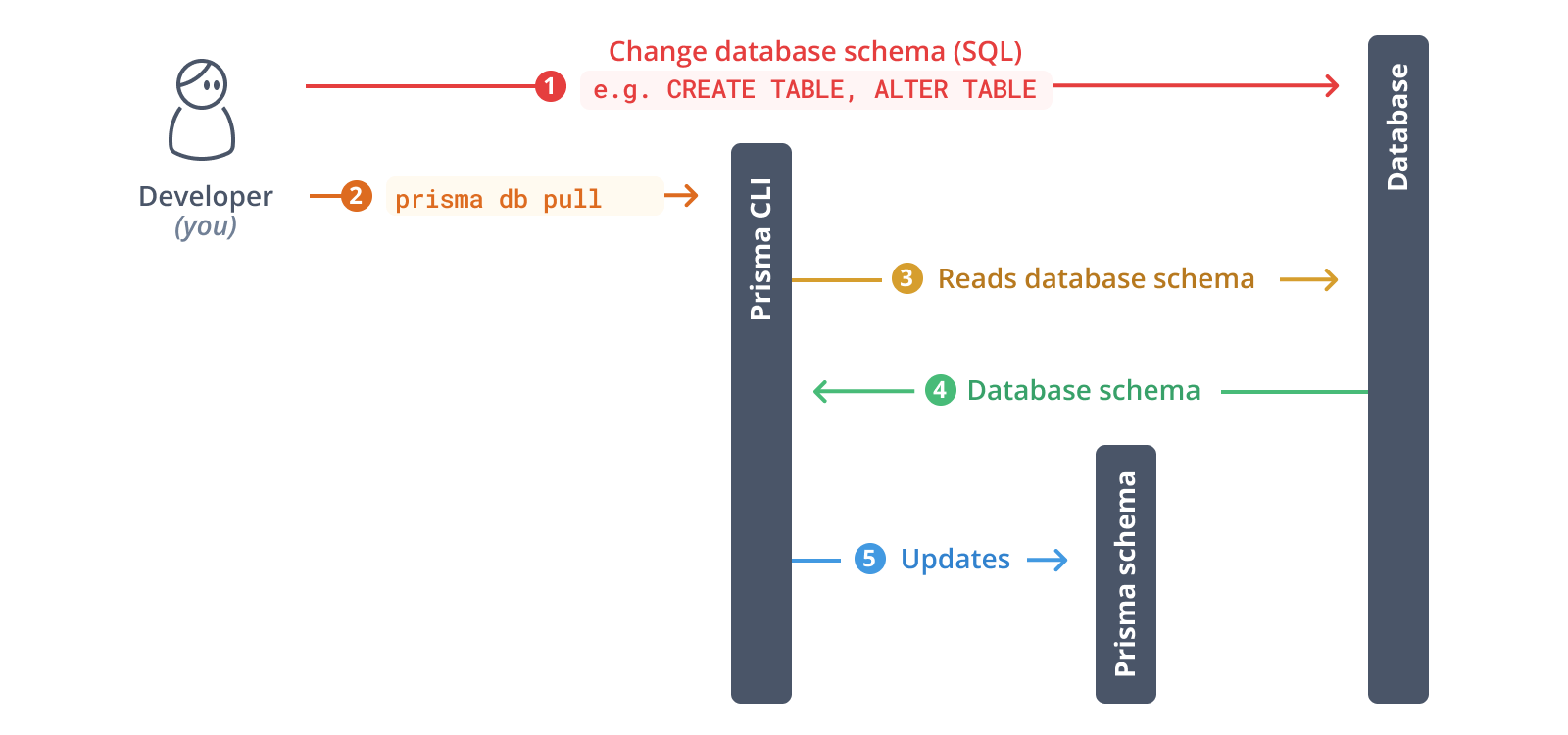
但是这两个命令都没有办法管理迁移历史,只是直接将 Prisma 结构同步到数据库(或将数据库同步到 Prisma 结构)当中。
这两个命令适用于项目创建的时候,或需要覆盖的时候。
带有迁移记录的同步
migrate dev
prisma migrate dev 记录迁移记录并更新数据库结构,执行时有如下几部操作:

当用户更新数据库结构后
执行了
prisma migrate dev命令根据更新的结构与数据库的差异生产改动部分的 SQL 并保存在 migrations 文件夹下
插入一条迁移记录到数据库表中
完成数据库结构更新
这条命令中,你也可以加上 --create-only 参数来实现只生成SQL 的迁移:
prisma migrate dev --create-only
这样你可以自定义编辑这次迁移。
例如,如果要在不导致任何数据丢失的情况下重命名列,或者加载数据库扩展(在 PostgreSQL 中)和数据库视图(当前不支持),则可能需要编辑迁移。
migrate deploy
prisma migrate deply 可以将 migrations 中还没有应用的结构应用到数据库结构当中
前面说到的自定义迁移在编辑过 SQL 文件之后就可以使用 migrate deply 应用到数据库当中,当让你也可以手动执行 SQL 文件,但是数据表中 migrations 迁移记录就没有办法记录了。
migrate deply 执行时有如下几部操作:
比较数据表中的迁移记录还找到还没有应用的迁移记录
执行迁移 SQL
更新迁移数据表

migrate deply 通常用于生产环境的部署当中,但是部分情况下如果 Prisma Client 无法连接到生产环境数据库也可以手动完成这个步骤。
现有项目接入 Prisma Migrate
由于 migrate dev 和 migrate deply 都需要对比之前的迁移记录,所以不能直接从已有项目接入 Prisma Migrate。
我们需要补充之前的数据库迁移记录,当然,从现在这个时间点记录迁移就可以了
生成第一次迁移记录
prisma migrate diff --from-empty --to-schema-datamodel ./prisma/schema.prisma --script > migration.sql然后将 /migration.sql 复制到 /migrations/20241113065155_init 目录下
migrations/
└─ 20241113065155_init/
└─ migration.sql然后 migrate resolve 表示这条记录已经应用过了
prisma migrate resolve --applied "20241113065155_init"
这样数据库中就有了这次初始化记录,之后就可以用 Prisma Migrate 的流程来进行开发了!
推荐工作流
结合代码仓库分支合并使用 CI 系统(例如 GitHub Actions)使用 prisma migrate deploy 将 Prisma 架构和迁移历史记录与生产数据库同步

Prisma Migrate Diff
这几个 diff 参数每次用之前都需要查一次,故放在此统一记录
比较来自两个任意来源的数据库架构,并将差异输出
参数
尾巴
工作需要的原因需要学习 Prisma Migrate 的使用,但是自己学习的时候发现没有特别通俗易懂的文档,在柯老师(Claude)的帮助下总算是搞清楚了 Prisma Migrate 到底是怎么一回事,也勉强算搞清楚怎么用了,写一点东西复盘总结,以便来日温故复习。